
La storiografia ai tempi dell'IA
Eseguendo uno stesso prompt, i Large Language Models sono in grado di annotare la storia in modo replicabile e valutabile in modo quantitativo. Questo cambia tutto.

Un sondaggio prima di iniziare
Vado subito al punto: sto pensando di fare un podcast in cui descrivo le 300 e più società presenti nel Chronos dataset attraverso i dati che ho raccolto. Lo ascoltereste? o preferite leggere e vedere i grafici? E che durata dovrebbe avere una puntata del podcast? Lancio un sondaggio che lascerò aperto per i prossimi 3 giorni.
1. Large Language Models come Annotatori
La storiografia è la disciplina che lavora sulle interpretazioni degli eventi storici passati, basandosi su un’indagine critica e principi metodologici consolidati. Chiaramente l’interpretazione della storia è un compito molto soggettivo e delicato, perché può spesso toccare le radici delle nostre identità.
Qualche settimana fa ho presentato a Cagliari un articolo (lo potete trovare qui, se volete approfondire) che testava se sia possibile usare machine learning e soprattutto i Large Language Models (LLM) per aiutarci nelle interpretazioni storiche. Riassumo tutto per chi non lo ha letto, se lo avevate letto potete saltare questa parte.
INIZIO RIASSUNTO
Nell’articolo scientifico ho usato la Structural Demographic Theory come schema interpretativo per identificare cicli storici che si ripetono nei dati, è una teoria che ho usato tantissimo nelle analisi storiche fatte su questo blog. Lo schema è questo:
fase 1. Crescita (un nuovo ordine crea coesione sociale, innescando un'elevata produttività e aumentando la competizione per lo status sociale. Ad esempio l’Italia anni ‘60);
fase 2. Impoverimento della popolazione (l'aumento della competizione per status e risorse porta a una crescente disuguaglianza: Stati Uniti anni ‘70);
fase 3. Sovrapproduzione di élite (le disuguaglianze bloccano l’ascensore sociale, sfociando in fazioni radicali e in individui frustrati che frenano la produttività e possono diventare agenti d'instabilità: Italia anni 2000);
fase 4. Stress dello Stato (la mancanza di produttività genera difficoltà fiscali, e l’instabilità spinge lo Stato verso potenziali crisi con conflitti diffusi, fin quando il ciclo non riparte: Italia del presente).
fase 5. Crisi (un conflitto diffuso che porta a una ristrutturazione dell'ordine in una società: Stati Uniti nel 1935, Italia nel 1945);
La domanda è: l’Intelligenza Artificiale (Machine Learning o LLM) è in grado di riconoscere queste fasi, date delle descrizioni di periodi storici? I risultati erano estremamente interessanti perché anche se il machine learning ha performance basse, invece usando GPT-4 e Llama 3.1 large, due Large Language Models molto grandi, siamo riusciti a ottenere un accordo sull’annotazione delle fasi storiche definite dalla Structural Demographic Theory superiore a quello degli umani.
FINE RIASSUNTO
Sì, avete capito bene: superiore a quella degli umani. Non potevo esimermi dal fare nuovi esperimenti per essere sicuro di questa cosa. Ho lavorato sul tema e pubblicato un nuovo paper dove ho confrontato quanto gli umani e i Large Language Models sono in grado di interpretare la Structural-Demographic Theory partendo dalle stesse istruzioni. Presenterò questo paper domenica 26 Ottobre a Bologna alla facoltà di ingegneria informatica, in un workshop della Conferenza Europea sull’Intelligenza Artificiale (ECAI), per chi ci sarà ci vediamo lì. Vi confermo il fatto che i LLM molto grandi (con più di 400 miliardi di parametri) riescono ad annotare le fasi della Structural Demographic Theory da brevi descrizioni di periodi storici in maniera comparabile, se non superiore, a quella degli umani.
ATTENZIONE: non sto dicendo che i LLM comprendono la storia meglio degli umani ma che, nel categorizzare le fasi dei cicli storici, due LLM di grandi dimensioni annotano in maniera più consistente di due umani. In pratica sono più d’accordo tra loro.
Questo ha implicazioni enormi. Nonostante possano avere, come gli umani, dei bias dovuti ai dati di addestramento, i Large Language Models come annotatori storici hanno due enormi vantaggi:
sono infinitamente più veloci degli umani
seguendo uno stesso prompt possono annotare in modo replicabile, e soprattutto valutabile in modo quantitativo
Il punto 1 è ovvio (ho personalmente annotato a mano il Chronos dataset mettendoci circa un anno, un LLM potrebbe metterci pochi minuti), ma credo che il punto 2 sia quello più importante, perché forse possiamo usare gli LLM come annotatori per gestire la soggettività dell’interpretazione storica in maniera replicabile. Per approfondire questo aspetto ho voluto testare meglio questo punto. Conscio che cultura e censura possono avere un impatto sui bias presenti nei LLM, ho anche voluto provare ad aggiungere un LLM europeo: Mistral. Si tratta di una ricerca in fieri, per cui proverò testarne altri in futuro..
2. I risultati
Per prima cosa i risultati mostrano che non tutti i LLM sono in grado di annotare la storia. I modelli più piccoli, con meno di 100 miliardi di parametri, tendono a "allucinare", ovvero a generare informazioni malformate, imprecise o addirittura inventate. Al contrario, i giganti sopra i 400 miliardi di parametri, come GPT-4 e Llama3.1-405b, hanno dimostrato una precisione straordinaria, raggiungendo un livello di accordo nell’interpretazione della storia con la Structural Demographic Theory comparabile a quello tra due esseri umani. Le combinazioni di inter-annotator agreement che includevano Mistral-large 2411 invece si sono rivelate peggiori degli umani.
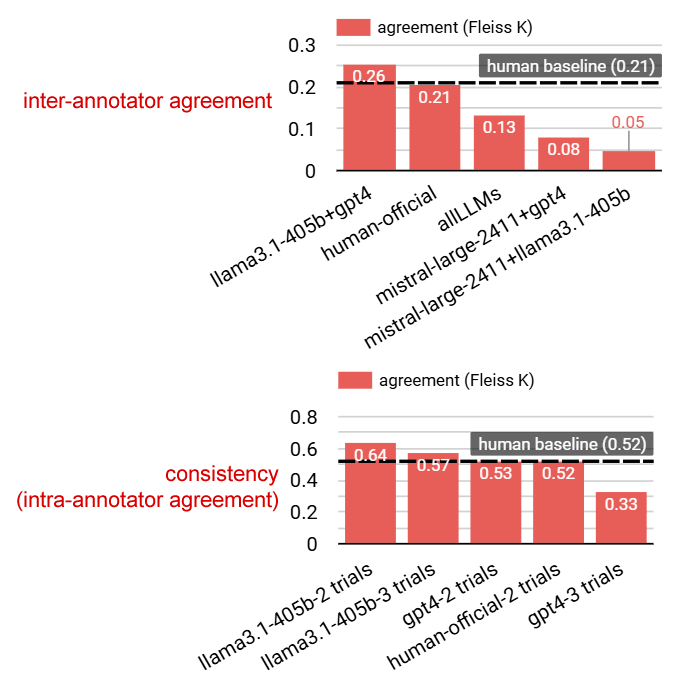
Ma quanto è replicabile il risultato ottenuto? Un LLM, se interrogato due volte sulla stessa cosa, potrebbe rispondere in modo diverso. Ho provato a testare questo aspetto abbassando la temperatura a zero e facendo fare più prove (trials) per capire quanto LLM e umani sono consistenti con sé stessi (intra-annotator agreement). Come mostra la figura, Llama3.1-large è più consistente dell’annotatore umano, mentre la performance di GPT4 tende a degradare dopo due trials.
3. Un nuovo digital divide
Tuttavia, c'è un ostacolo significativo: la democratizzazione della ricerca. L'enorme potenza computazionale richiesta per far funzionare questi modelli superiori a 400 miliardi di parametri è un lusso che non tutte le istituzioni possono permettersi. Le università e i centri di ricerca che conosco usano LLM su server interni e lavorano spesso con modelli piccoli, sotto i 100 miliardi di parametri. Questo crea un divario potenziale tra chi ha accesso a LLM abbastanza potenti per fare annotazioni di questo tipo e chi no. Da questo punto di vista mi ritengo fortunato: lavorando in azienda ho accesso a modelli grandi, ma mi rendo conto che molte università, almeno nel breve termine, non hanno le stesse possibilità. Università, istituti di ricerca e aziende private potrebbero unire le forze per condividere conoscenze e risorse, rendendo questi potenti strumenti accessibili a scopi di ricerca.
Come dicevo, sto per iniziare un interessante tour per confrontarmi con storici e computer scientists. Domenica 26 Ottobre presenterò questo lavoro a Bologna alla facoltà di ingegneria informatica, all’interno di un workshop della conferenza ECAI, penso che sarò a Bologna per un aperitivo dopo la conferenza, se qualcuno vuole unirsi mi scriva.
Nelle prossime settimane sarò prima a Siena, per confrontarmi con la comunità italiana degli storici, poi a Vienna per incontrare Peter Turchin e la comunità della cliodinamica. Ci sentiamo tra due lunedì, quando sarò a Siena. Il post sarà sull’impatto dei LLM sulla nostra memoria storica. A presto.